基础知识
- 强化学习基本概念
- 强化学习的类别
- 强化学习之MDP马尔科夫决策过程
- 价值与贝尔曼方程
- 动态规划 Dynamic Programming
- Monte Carlo and Temporal-Difference
- SARSA and Q-Learning
论文精读
- Energy-Based Hindsight Experience Prioritization
- Maximum Entropy-Regularized Multi-Goal Reinforcement-Learning
- Reinforcement Learning with Deep Energy-Based Policies
- Keeping Your Distance: Solving Sparse Reward Tasks Using Self-Balancing Shaped Rewards
Open AI
- Evolution Strategies as a Scalable Alternative to Reinforcement Learning
- Hindsight Experience Replay
- RL2: Fast Reinforcement Learning via Slow Reinforcement Learning
Deep Mind
- Prioritized Experience Replay
- Universal Value Function Approximators
- Asynchronous Methods for Deep Reinforcement Learning
论文浅读
- Massively Parallel Methods for Deep Reinforcement Learning
- Model-Based Reinforcement Learning via Meta-Policy Optimization
- Diversity is All Your Need: Learning Skills Without a Reward Function
- Curiosity-Driven Experience Prioritization via Density Estimation
- Continuous Deep Q-Learning with Model-based Acceleration
- Boosting Soft Actor-Critic: Emphasizing Recent Experience without Forgetting the Past
- Reinforcement Learning with Attention that Works: A Self-Supervised Approach
- Multi-focus Attention Network for Efficient Deep Reinforcement Learning
- Emergence of Locomotion Behaviours in Rich Environments
- Deep Exploration via Bootstrapped DQN
- Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
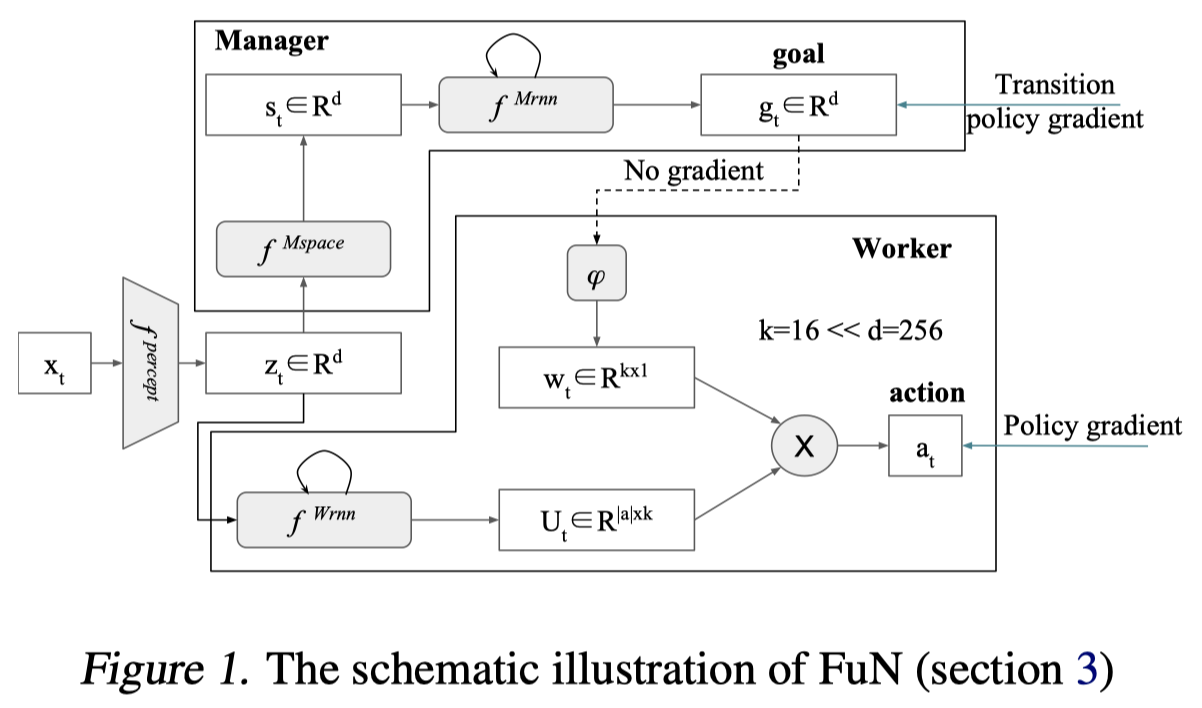
- FeUdal Networks for Hierarchical Reinforcement Learning
- Exploration By Random Network Distillation
相关信息
学习资源
- 《Reinforcement Learning : An Introduction 2nd Edition》——Sutton
- 基础必读
- 通俗易懂
- 数学公式很多,虽然很多不太实用,但对理解RL的精髓很有帮助
- Reinforcement Learning Course by David Silver, 2015
- 基础必看,讲述了强化学习的基础算法
- 有字幕,通俗易懂
- 有课件Slide
- OpenAI Spinning Up
- 深度强化学习
- 算法很多,解析也很清晰
- 有代码仓库,可以查看源代码,方便复现
- Medium : Reinforcement Learning
- 博文质量不错,内容涵盖基础与进阶
- 缺点:更新少
- StackOverflow : Reinforcement Learning
- 进阶必备
- 多看多交流可以加深自己的理解
不错的代码仓库
- TianShou——An elegant, flexible, and superfast PyTorch deep Reinforcement Learning platform.
- pytorch
- 清华开源,适合入门
- Rainy——☔ Deep RL agents with PyTorch☔
- 有一些比较难复现的算法,比如PPOC
- Machin——Machin is a reinforcement library purely based on pytorch. It is designed to be readable, reusable and extendable.
- pytorch
- 框架封装的比较好,覆盖算法很多,包括一些分布式、多智能体的算法实现
- RLcode——白话强化学习
- 每个算法极简实现,适合新手学习入门
- DeepRL_Algorithms——DeepRL algorithms implementation easy for understanding and reading with Pytorch and Tensorflow 2
- Pytorch 和 tensorflow2
- 结构清晰,算法多